文部科学省委託事業 標準規格の拡大教科書等の作成支援のための調査研究 「拡大教科書の効率的な作成方法について」 平成23年3月
6 データ・資料等
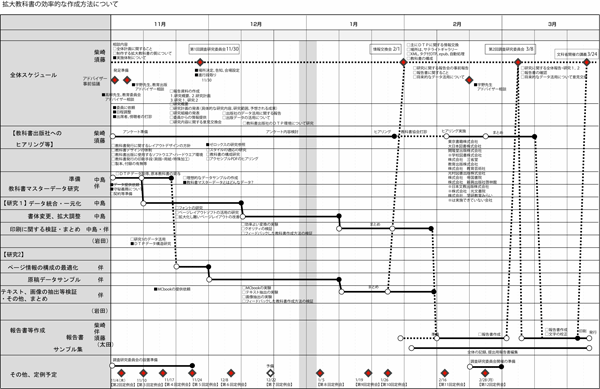
6.1 研究実施スケジュール
6.2 主な文字化けの事例とその原因
テキストを含む文書データ等を編集・閲覧ソフトで開いた時、本来指定した文字と異なる字種・字形で表示される状態を文字化けという。作成時と異なるPC環境で文書データを開いた場合、同一環境でも異なるソフトで表示した場合、編集ソフトでテキストのフォントを変更した場合、文書データを別のデータ形式で保存し、これを表示した場合などに文字化けが生じる。文書データを別のデータ形式で保存した場合、保存データにフォント属性を保持できない仕様(テキストデータ形式など)であれば、これを表示するソフトによって表示フォント環境は異なる。従って、ユーザが任意にフォントを変更して生じる文字化けとデータ形式を変更して生じる文字化けでは、共通してフォントが原因となるが、文字化けを防ぐ対処ができるかどうかやその方法は異なる。
1つのフォントでは一貫したポリシーですべての文字の形状がデザインされており、これを書体という。この書体を変更する目的でテキストのフォントを変更することが多い。(参照:図の(a)フォント変更例)。フォントは、基本ソフトに使用する標準フォントの他に市販のフォントや出版社が自社用に作成したオリジナルフォントなどがあり、PCごとに搭載されているフォントの数・種類は異なる。市販フォントを使用した書類データを標準フォントしかないPCで開いた場合、市販フォントの書体で表示することはできない。通常同じ基本ソフトを使用していれば標準フォントだけ利用することでこのような問題は回避できる。この使用フォントの有無による問題は、必ずしも文字化けの問題にはならない。文字化けではないが、フォント変更で字形が変わる場合はある(参照:図 の(b)フォント変更で字体が変わる例)。
フォントに格納される文字は規格によって字種ごとにコード番号付されており、これを文字コードという。日本語の場合、文字コード規格にはShift_JISとUnicodeがある。最近の基本ソフトの標準フォントは、ほとんどUnicodeに対応している。例えば「あ」という字種は、Unicodeでは「U+3042」というコード番号が割り当てられている。規格に準拠していればどのようなフォントでもUnicodeで指定された場合、「U+3042」は「あ」が表示されることが保証される。
フォントには複数の文字が格納されているが、フォントの種類によってその文字数は異なる。扱える文字数は、日本語中心のShift_JISコードが1万程度であるのに対し多言語対応のUnicodeは6万以上ある。フォントに格納されている文字数は、このいずれの文字コードに対応したものかによって異なる。例えば、Unicodeではハングル文字を割り当てる文字コード群が用意されており、Windowsの標準フォントMS Pゴシック体などではこの文字の利用が可能である。しかしShift_JISコードに対応する文字数しかないフォントではハングル文字は扱えない。対応コードの違いから該当文字が表示できないものは、文字がセットされていないことを示す記号(四角に×印)などに置き換えて表示される。
またUnicodeに対応したフォント同志でも、一方はある文字がセットされているが、他方ではその文字コードに文字がセットされていない場合もある。このような全コードに対する実際の文字の実装状態よって扱える文字数は異なる。ある文字フォント指定してもその文字コードに実体となる文字がセットされていなければ、その文字がフォントにないことを示す記号が表示される(参照:図 の(c)変更先のフォントに文字コードに文字がセットされていないことで生じる文字化け例)。
市販フォントで外字フォントと呼ばれるものがあり、文字コード番号の体系は規格に即しているが、割り当てられている字種が規格とは異なるといったものがある。主にShift_JIS対応フォントが中心に利用されていた頃、そのコード数に制限があることから「異体字」「旧字体」「特殊記号」など通常のフォントに含まれない字種を利用するために開発されたフォントである。例えば、Shift_JISのコード番号「0x42」は、「B」の字種を割り当てることになっているが、外字フォントでは「kg」のようなまったく異なる字種が割り当てられている場合がある(参照:図 の(d)変更元のフォントの文字コードに規格と異なる文字がセットされていることで生じる文字化け例)。
Unicodeでは多くの異体字を持つことができる。字義が同じで字体の異なるものをいい、「鴎」の異体字として「鷗」がある。基本となる字体「鴎」に文字コードには割り当てられ、異体字には割り当てられない。異体字にするためには特殊な指定方法が必要となるが、現状ではこの指定機能をもつソフトは一部のDTPソフトなどに限定されている。フォントによって異体字は漢字以外にも多数の記号類が用意されている場合がある。例えば、ひらがなの「あ」に対して異体字となる記号類は「(あ)」「○付のあ」「□付のあ」「黒丸に白抜きのあ」などがある。こうした異体字の充実したフォントを利用することで外字フォントを使用しなくても、多様な字種、記号を扱えるようになった。しかしながらDTPソフトなどで指定した異体字をコピーし、別のテキストエディターのデータにコピーした場合、基本字種に置き換わる場合がある(参照:図 の(e)異体字の指定が解除され標準字形に置き換わる例)。このようにある環境下で指定したフォント1で利用可能な異体字「X’」は、別の環境にコピーした時に基本字種「X」に文字化けする可能性がある。これは、基本字種「X」に対する指定属性が異体字「X’」をコピーしたり、書き出したりした時点で失われることが原因となる。
以上のように文字化けが生じる原因は、複雑といえる。
文書データを作成したソフトとフォントが利用できる制作環境であれば、これを回避することも可能である。図の(c)のような文字化けは、同じコードに同じ文字がセットされているフォントで指定変更することで回避できる。外字フォントを使用しないことで図の(d)のような問題を回避できる。
しかし、文書データのテキストを別のデータ形式に書き出したり、テキストをコピーし、別のソフトのデータにコピーしたりする場合、フォント指定情報が失われる場合がある。フォント属性をもたないテキストは、一般的に基本ソフトの標準フォンで表示されるため。図(c)や図(d)の問題が生じる可能性がある。同時に異体字の指定も失われるため図(e)の問題も生じる場合がある。
DTPソフトでフォント指定の可能な環境で編集しているならばともかく、汎用的にデータを利用する場合、フォント属性を持たないテキストデータとする。この場合、フォントを選んで文字化けを解消することはできないため、文字化け回避の対策としては、標準フォントが実装する文字の範囲内で文書を表現し、異体字の利用は避けるといったことが必要となる。
最も互換性を高めるには、標準フォントで入力した字種のみでテキストデータを作成し、これに対して各種フォントを指定する方法である。このテキストデータは標準フォントを再指定しても文字化けは生じない。逆にこうした互換性を確保できるフォントであればオリジナルフォントを利用しても問題は少ない。

- 【図68】
6.3 出版社が教科書コンテンツのテキストデータを独立したファイルで保持していない理由
教科書コンテンツの文字情報は、原稿作成段階ではテキストデータ(初期原稿)として存在したとしても、デザイン・レイアウトを行う段階からページレイアウトソフトで作成するページレイアウトデータに取り込み、その中で編集が始まる。また、直接ページレイアウトデータ上にテキスト入力する場合もある。教科書コンテンツは、検定審査終了までにページレイアウトデータの中で繰り返し修正され、最終的には初期原稿とはほぼ異なるものになる。従って最終的な教科書コンテンツの文字情報は、独立したテキストデータではなく、ページレイアウトデータ中にのみ存在することが多い。デジタル環境で文字情報を扱うためにはテキストデータ形式がもっとも利用しやすいが、教科書の場合このような制作経緯があり、ページレイアウトデータから抽出しなければ得られない。尚、ページレイアウトデータの中のテキスデータは、ワープロソフトのように1ファイル中に連続したものではなく、多数分割されているため、すべてのテキストを一度に選択し、コピーを行うことは不可能である。
6.4 PDFデータからテキストを抽出する際の問題一覧
| 問 題 | 内 容 | 原 因 |
| ・抽出方法の問題 | Adobe Readerでのテキストの抽出方法は、以下の2種類がある。 (a)テキストコピー:画面上のテキスト箇所を選択コピーし、ワープロソフトに貼り付けする。 (b)テキスト保存:テキストデータのみを別名で保存する それぞれ結果が異なり、いずれも不具合がある。 |
PDFの仕様。 |
| ・情報の順序の問題 | 抽出後、文字情報の順序がばらばらになり、レイアウト順に抽出されない。 | PDFの仕様。情報順序は、配置要素のレイヤー順に依存する。 |
| ・改行の問題 | 抽出後、不要な改行が入る。文章の途中で強制改行ではなく、自動折り返ししている箇所で強制改行が挿入されてしまう。 | PDFの仕様。 |
| ・フォントの問題 | 抽出後、異体字、記号等が文字化けする。 | 標準フォントに含まれないオリジナルフォントや商用フォントの異体字・特殊記号を使用している。 |
| ・その他の問題 | 抽出できない。 | テキストが図形化、画像化されている場合、テキストとしてコピーできない。 |
6.5 PDFデータから画像を抽出する際の問題一覧
| 問 題 | 内 容 | 原 因 |
| ・抽出方法の問題 | Adobe Readerでの画像の抽出方法は、以下の1種類しかない。 (a)画像コピー:画面上の画像箇所を選択コピーし、Windows標準画像編集ソフト(ペイント)などに貼り付けする 特に図・写真等が多いPDFデータから個別に抽出を行うのはかなりの時間を要する。 |
Adobe Readerでは、画像抽出の一括処理ができない。 |
| ・データ形式の問題 | 抽出できない。 | ベクトル図形データは、抽出ができない。 |
| ・再現性の問題 | PDF閲覧時の画像イメージと抽出データが異なる。 | 原因1:Adobe InDesignで配置された画像にサイズ変更、トリミング(画像の一部分を表示する)等の加工を行った場合でも、抽出データはAdobe InDesignでの加工に影響されず元のデータのままである。 原因2:Adobe Photoshopなど画像編集ソフトでクリッピングパス機能を利用して切り抜き(屋外で撮影した人物写真で、人物のアウトラインを指定し、人物以外の背景を表示させないなど)の設定を行った場合でも、抽出データにはAdobe Photoshopの設定は反映されない。 原因3:Adobe InDesignの配置画像に透明効果を設定し、PDF 1.3の形式でPDFデータを作成した場合、透明の分割・統合が実行され、該当箇所の抽出データは、イメージや色が異なる。 |
| ・画像が分割される問題 | Adobe Acrobatですべての画像を書き出す機能を利用した時、PDF上では1つの画像が分割されて保存される。 | Adobe InDesignで配置された画像にぼかしなどの効果を設定した場合、抽出データは、ぼかし箇所とぼかしが適用されていない箇所に分割された複数データが書き出される。なお、Adobe Readerで該当箇所を画像コピーした場合は、分割されないが、ぼかし効果は適用されない(前述の再現性の問題)。 |
| ・画像が分割できない問題 | 重なっている画像が別々に使えない。 | 複数の画像を重ねたイメージの1ファイル画像は、それ以上分割して抽出できない。 |
| ・カラーモードの問題 | 色味が異なる。 | PDFのカラーモードがCMYKの場合、ペイントのカラーモード変換エンジンによりRGBに変換される。元の画像の色味によって変換後の色の見え方に差が生じる。 |
| ・解像度の問題 | 抽出画像をワープロソフトに配置すると表示サイズが異なる。 | PDFの画像は高解像度(300ppi以上)だが、ペイントでは低解像度(72ppi, 96ppi)に変換される。総画素数に変更はないが、解像度が低くなるため相対的に表示サイズが大きくなる。 |
6.6 DTPデータから抽出したXMLデータ例
<?xml version=”1.0″ encoding=”UTF-8″ standalone=”yes”?>
<Root><div><h2>1 線対称<img href=”file:///C:/xxx/sansu6/images/img_head2_bg.eps”></img> </h2><h3> 1 <img href=”file:///C:/xxx/sansu6/images/img_head3_bg.eps”></img> </h3><p>7ページのくの形は、2つに折ってぴったり重なる形です。 </p><p>方眼紙を切って、くの形をつくってみましょう。<img href=”file:///C:/xxx/sansu6/images/img010101_01.eps”></img> </p><p> </p><p><img href=”file:///C:/xxx/sansu6/images/img_point_icon.eps”></img> 方眼紙を2つに折って、その一方に下の左のような形をかきましょう。 </p><p>線にそって切り取り、方眼紙を開いてみましょう。<img href=”file:///C:/xxx/sansu6/images/img010101_02.eps”></img> </p><div> </div><p> </p><p>1つの直線を折り目にして折ったとき、折り目の両側がぴったり重なる図形は、<em><aid:ruby xmlns:aid=”http://ns.adobe.com/AdobeInDesign/3.0/”><aid:rb>線対称</aid:rb><aid:rt>せんたいしょう</aid:rt></aid:ruby></em>または<em>直線について対称</em>であるといいます。 </p><p>また、その折り目にした直線を<em>対称の<aid:ruby xmlns:aid=”http://ns.adobe.com/AdobeInDesign/3.0/”><aid:rbc><aid:rb>軸</aid:rb></aid:rbc><aid:rtc><aid:rt>じく</aid:rt></aid:rtc></aid:ruby></em>といいます。 </p><p> </p><p> </p><h3> 2<img href=”file:///C:/xxx/sansu6/images/img_head3_bg.eps”></img> </h3><p>右の図形で、対称の軸で折り重ねたとき、重なる点や直線について調べましょう。<img href=”file:///C:/xxx/sansu6/images/img010102_01.eps” alt=”対象の軸 A B C D E F G H I J K L”></img></p></div>
</Root>
6.7 XML表示用HTMLをウェブブラウザで表示した例
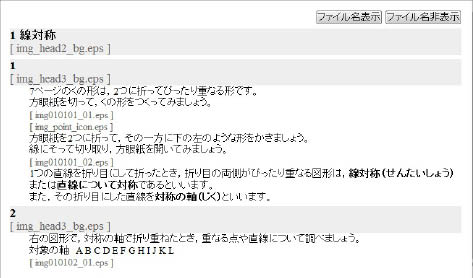
6.8 XML表示用HTMLコード
XMLをウェブブラウザでテキスト表示するために利用するHTMLのソース例(Internet Explorer のみ対応)。「//読み込むXMLファイル名指定」の下の行にあるXMLファイル名を変更することで処理対象ファイルを変更できる。
<html xmlns=”http://www.w3.org/1999/xhtml”>
<head>
<meta http-equiv=”Content-Type” content=”text/html; charset=utf-8″ />
<title>サンプル</title>
<script type=”text/javascript”>
//読み込むXMLファイル名指定
var xmlFileName=”sansu6.xml”;
</script>
<style type=”text/css”>
<!– (中略) –>
</style>
<script type=”text/javascript”>
var gCldObj=MM_xml01();
function MM_xml01(){
var docObj=new ActiveXObject(“Msxml2.DOMDocument”);
docObj.async=false;
docObj.load(xmlFileName);
var rootObj=docObj.documentElement;
var cldObj=rootObj.childNodes;
return cldObj;
}
var gAgent;
var gEventId;
var arr=new Array();
var tagSymSS=”\<“;
var tagSymEnd=”\>”;
var tagSymES=”\<\/”;
var flg=0;
var gContents=””;
var gBtnId=””;
var gTableRows=0;
var gTableCols=0;
var gTableRowsNum=0;
var gTableColsNum=0;
MM_addEvent(window, “load”, MM_setting);
function MM_addEvent(e,f,g){
if(e.attachEvent){
e.attachEvent(“on”+f, g);
gAgent=”ie”;
}
if(e.addEventListener){
e.addEventListener(f, g, false);
gAgent=”modern”;
}
}
function MM_setting(){
var formObj=document.getElementsByTagName(“form”)[“form1”];
arr=formObj.getElementsByTagName(“input”)
for(i=0; i<arr.length; i++){
if(arr[i].type==”button”){
MM_addEvent(arr[i], “click”, function(e){ MM(e);} );
}
}
MM_changeInnerHtml(“viewImgName”);
}
function MM(e){
var obj=MM_eventObj(e);
MM_changeInnerHtml(obj.id);
}
function MM_eventObj(e){
var obj;
if(gAgent==”ie”){
obj=e.srcElement;
}else{
obj=e.target;
}
return obj;
}
function MM_changeInnerHtml(e){
gContents=””;
gBtnId=e;
MM2(gCldObj);
var obj=document.getElementById(“viewArea”);
obj.innerHTML=gContents;
}
function MM2(e){
for(var i=0; i<e.length; i++){
var tagName=e[i].nodeName;
var tagType=e[i].nodeType;
if(tagType!=1){
var tagText;
if(e[i].nodeValue==undefined){
tagText=””;
}else{
tagText=e[i].nodeValue;
}
}
if(tagType==1){
var test=MM_tagStart(tagName,tagType,tagText,e[i]);
}
MM2(e[i].childNodes);
}else{
MM_contentsText(tagName,tagType,tagText,e[i]);
tagText=””;
}
if(tagType==1){
MM_tagEnd(tagName,tagType,tagText,e[i]);
}
}
}
var imageTag= “span”;
function MM_tagStart(e,f,g,h){
if(e.match(/^img/)){
e=imageTag;
}
if(e.match(/^aid:rt$/)){flg=1;
}
if(e.match(/^aid:/)){
>e=”span”;
}
if(e.match(/^table$/)){
gTableRows=h.getAttribute(“aid:trows”);
gTableCols=h.getAttribute(“aid:tcols”);
}
gContents+=(tagSymSS+e+tagSymEnd);
if(e.match(/^th$/) || e.match(/^td$/)){
if(gTableColsNum==0){
gContents= “<tr>”+gContents;
}
}
return e;
}
function MM_contentsText(e,f,g,h){
if(e.match(/^img/)){
var obj=h;
var imgText= “”;
if(obj.getAttribute( “alt”)){
var altText=obj.getAttribute( “alt”);
imgText+=(“<br />”+altText+”<br />”);
}
if(gBtnId== “viewImgName”){
if(obj.getAttribute( “href”)){
var pathName=obj.getAttribute( “href”);
pathName=MM_serchWord_fromEnd(pathName, “\/”);
imgText+=( “<span class=’pathName’>[ “+pathName+” ]<\/span>”);
}
}
g=imgText;
}
if(flg){
g=”(”+g+”)”;
}
if(g!=undefined){
gContents+=(g);
}
}
function MM_tagEnd(e,f,g,h){
if(e.match(/^img/)){
e=imageTag;
}
if(e.match(/^aid:/)){
e=”span”;
flg=0;
}
gContents+=(tagSymES+e+tagSymEnd);
}
}
}
function MM_serchWord_fromEnd(e,f){
var index;
for(var i=e.length-1; 0<=i; i–){
var chr=e.substr(i,1)
if(chr==f){
index=i;
break;
}
}
return e.substring(index+1, e.length);
}
</script>
<body>
<form id=”form1″ action=””>
<input type=”button” name=”viewImgName” id=”viewImgName” value=”ファイル名表示” />
<input type=”button” name=”hiddenImgName” id=”hiddenImgName” value=”ファイル名非表示” />
</form>
<div id=”viewArea”>
</div>
</body>
</html>
6.9 XML表示用HTMLについて
データは、HTMLファイルとXMLファイルを提供する方法とHTMLファイルをウェブブラウザで表示した時のテキストをテキストファイルにコピーし提供する方法が考えられる。今回は前者を前提にしている。基本的にはHTMLファイルをダブルクリックすればウェブブラウザInternet Explorerが起動し、テキストを表示できるため操作は容易である。HTMLファイル名は任意に指定できるため「テキスト表示用.html」などとすればより扱いやすく、HTMLファイルとXMLファイルの誤認を避けられる。XMLデータサイズが大きくなると表示に時間を要する可能性があるため、章ごとにデータを分割するなど考慮は必要である。
今回作成したHTMLデータでは、ウェブブラウザに表示されるボタンの操作で図・写真等の外部ファイル名の表示を切り替えることができる。教科書コンテンツの文字情報のみをコピーしたいときは、これら外部ファイル名は非表示にしておき、文字情報のどの箇所で図・写真等を使用しているか確認する場合は、外部ファイル名を表示することができる。HTMLファイルにすることでこのようなプログラム機能を付加したデータ提供が可能である。また、プログラムの調整することで、教科書全体のデータから特定の章のテキストだけを検索し、表示させる機能や見出しや本文などに文字スタイルを指定して表示する機能などを追加することも考えられる。これ以外にXMLファイルそのものをWordに読み込んで、そのデータ構造を生かし、文字スタイルを自動的に割り当てることも考えられ、制作時の効率化の可能性がある。
6.10 アクセシブルPDFの作成、テキストデータの抽出検証
PDFには、音声読み上げに対応したアクセシブルPDF形式がある。この形式に対応することでPDFからテキストの抽出が行いやすくなるかを検証した。アクセシブルPDFは、(a)作成されたPDFデータをAdobe AcrobatのTouchUp 読み上げ順序の機能を利用して文字情報を要素ごとにタグ付し、要素の順序を調整して作成する方法、(b)Adobe InDesignで文字情報を要素ごとにタグ付し、要素の順序を調整してからPDFを作成する方法がある。
Adobe Acrobatで編集する場合は、対象となる文字情報を一つずつ範囲選択し、タグ付する必要があり、かなり時間を要する。特に縦組みの場合は、1行ずつタグ付を行わなければならないため、長文をこれで編集するのは、現実的でない。一方、Adobe InDesignで作成する場合は、要素を適切な順序・階層に組み合わせデータ(参照:5.3 検証1(2)情報の構造化)を利用すれば、作成時に一般オプション「タグ付きPDFを作成」をチェックすることでアクセシブルPDFが作成できる。
それぞれの方法で作成したPDFデータをAdobe Readerで開き、(a)テキストコピー、(b)テキスト保存の方法でテキストの状態を確認した。Adobe Acrobatで編集したデータの場合、(a)テキストコピー、(b)テキスト保存とも情報の順序・改行の問題は生じなかった。Adobe InDesignで作成したデータの場合、(a)テキストコピーでは、情報の順序の問題が生じ、(b)テキスト保存では、改行の問題は生じた(参照:6.4 PDFデータからテキストを抽出する際の問題一覧)。その他に(1)(2)共通してグループルビが対象となる漢字の途中に配置される問題、(a)テキストコピーの場合、画像のAlt属性に指定した代替テキストがコピーされない問題などがある。アクセシブルPDFにすることで従来のPDFのテキスト抽出の問題の一部は改善されるが、すべての問題をクリアにすることは現段階では、困難である。
6.11 抽出する画像データのカラーモードと解像度
DTPデータで使用する画像データのカラーモードは、CMYKであるが、Wordなどワープロソフトの基本カラーモードはRGBであり、CMYKの画像データを配置したとしてもWordのカラーモード変換エンジンによりRGBに変換されてしまう。このため提供データのカラーモードもRGBとした。DTPデータで使用する画像データは、高解像度(300ppi以上)であるが、オンデマンド印刷機で印刷される拡大教科書では200~300ppiでその機種に適した画質を得られる。作成検証時には200ppiに設定した。
6.12 Adobe Photoshopの一括処理機能
Adobe Photoshop CS5でも画像変換の一括処理(バッチ処理、イメージプロセッサー)を試したが、次の問題があり、推奨できない。Adobe Photoshop でEPSデータを開く時、画像解像度の指定をする必要がある。バッチ処理を行うとEPSデータを開くたび、画像解像度とカラーモードを手動で指定しなければならず、自動化ができない。イメージプロセッサーの場合、解像度が初期値の72ppiに固定され、適切な解像度が得られない。
6.13 EPUBの仕様等
| 規格開発組織、提供企業 | 国際電子出版フォーラム(IDPF:International Digital Publishing Forum) |
| 閲覧形式 | コンテンツ・ビューア分離型(EPUBファイル/iBooksアプリ(バージョン1.2.1)) |
| コンテンツデータの規格 | EPUBファイルは、XHTMLとCSS、画像によるウェブ形式のコンテンツデータ、出版物情報や目次などXML形式のデータをZip形式で圧縮し、パッケージ化したもの。DTBook形式のコンテンツデータにも対応し、DAISY形式のデータを作成することが可能。kindleへの変換が可能。 |
| 制作ツール | テキストエディタ、Zip圧縮ツールなど、SigilなどEPUB編集ツールもある。 |
| コピープロテクト、利用制限 | DRM(デジタル著作権管理)は、App StoreでのFairPlay方式を採用している。 |
| 対応デバイス | iPhone/iPad、Androidスマートフォン。 |
| ライセンス等 | なし。 |
| 書体指定 | iPad標準書体をCSSで指定。 ※ヒラギノ角ゴ ProN W3, W6。文字コードは、Adobe-Japan1-6のJIS2004字形に準拠。 |
| 外字 | 画像で代替。 |
| ルビ | 未対応(EPUB3.0で対応)。 |
| 縦中横 | 未対応。 |
| 段落、文字スタイル | CSS規格に準ずる。 |
| レイアウト、視覚表現 | CSS規格に準ずる(ウェブブラウザSafariと同等のレイアウト表示)。 |
| 改ページ | 対応。 |
| 柱 | 未対応。 |
| 目次(リンク) | 対応。 |
| 書体 | 変更不可(iBooks標準英語6書体のみ変更可能)。 |
| 文字サイズ | 変更可。 |
| 行送り | 変更不可。 |
| 文字間 | 変更不可。 |
| 縦組み | 未対応(EPUB3.0で対応)。 |
| 見開き | 端末横置きで見開き表示。 |
| 段組み | 未対応。 |
| ルビ | 未対応(EPUB3.0で対応)。 |
| 読み上げ | iPadのアクセシビリティ機能を利用し、テキストの読み上げが可能。 |
6.14 MCBookの仕様等
| 規格開発組織、提供企業 | 株式会社モリサワ |
| 閲覧形式 | コンテンツ・ビューア一体型(iPadアプリ)とコンテンツ・ビューア分離型(MCCファイル/MCBookビューア)がある。今回はiPadアプリを作成した。 |
| コンテンツデータの規格 | MCCファイルは、MCBook独自のタグ付きテキストデータとフォントがパッケージ化されたもので他のデータ形式と互換性はない。 |
| 制作ツール | Adobe InDesign, MCBookソリューション。 |
| コピープロテクト、利用制限 | DRM(デジタル著作権管理)は、App StoreでのFairPlay方式を採用している。Adobe InDesignから抽出したタグ付きテキストデータはテキストコピーにプロテクトをかけており、他のアプリケーションでは利用できないようにしている。フォントも同様。 |
| 対応デバイス | iPhone/iPad、Androidスマートフォン。 ※検証時のMCBookシステムは、バージョン2であるためAndoridに対応していない。 |
| ライセンス等 | システムの年間ライセンス料、ロイヤリティが必要。 |
| 書体指定 | データにMCBookバンドル書体を埋め込むことが可能。 ※リュウミン L-KL /中ゴシックBBB/太ミンA101/太ゴB101/見出ミンMA31/見出ゴMB31/新ゴ L/新丸ゴ L/ゴシックMB101 Lから3書体を使用。かなフォント/リュウミン L-KS/リュウミン L-KO/アンチックAN L/ゴシックMB101 L-KS/ネオツデイ L-KL/ネオツデイ L-KS/丸ツデイ L/丸アンチック L/ららぽっぷ Lと組み合わせて使用することが可能。文字コードは、Adobe-Japan1-6のJIS2004字形に準拠。 |
| 外字 | 画像で代替、サイズ変更に対応。 |
| ルビ | 対応(モノルビ、グループルビ)。 |
| 縦中横 | 対応。 |
| 段落、文字スタイル | 独自の段落、文字スタイル(Adobe InDesignのスタイルを流用可能)※書体指定、サイズ、色、行揃え、行送り、インデントなど |
| レイアウト、視覚表現 | 複数要素を含む複雑なページレイアウトに対応していない。 |
| 改ページ | 対応。 |
| 柱 | 対応。 |
| 目次(リンク) | 対応。 |
| その他 | HTML、ムービーデータの埋め込みが可能。 |
| 書体 | 埋め込み書体の中から切り替えが可能。 |
| 文字サイズ | 変更可。 |
| 行送り | 変更可。 |
| 文字間 | 変更可。 |
| 縦組み | 対応。 |
| 見開き | 端末横置きで見開き表示。 |
| 段組み | 文字サイズを小さくした時、一行長に応じて自動的に2段組に表示切替が可能。 |
| ルビ | 表示切替可能。 |
| 読み上げ | 未対応。 |
6.15 テキストフレーム・画像の配置方法による情報構造化作業の違い
InDesignデータ内のテキストフレーム・画像の配置方法により情報構造化の作業効率が異なる。下記の4つの方法でデータを作成し、情報構造化の作業内容を比較検証した。
- ①1ページ、複数テキストフィールド(テキストは非連結、画像は独立)
- ②1ページ、複数テキストフィールド(テキストは連結、画像は独立)
- ③1ページ、1テキストフィールド(画像は独立)
- ④1ページ、1テキストフィールド(画像はインライン画像かアンカー付きオブジェクト)
作成したデータには、以下が共通して設定されている。
- データのテキストには、段落スタイル、文字スタイルが適用済み
- タグ登録済み、タグ付きプリセットオプション設定済み
※タグ付きプリセットオプションであらかじめテキストフレーム、画像、表などの対象に割り当てるタグを設定しておき、「自動タグ」を実行することでタグ未適用要素に対し、自動的にタグ適用させることができる。今回は、テキストフレーム=div、画像=imgとした。「スタイルをタグにマップ」の機能では段落スタイルをもたない画像に対しタグを割り当てられないため、この機能を利用すると効率が良い。
①1ページ、複数テキストフィールド(テキストは非連結、画像は独立)
定型的でないレイアウトの場合、テキストフレームを分けて任意の位置に配置を行う場合が多い。
情報構造化の手順
- 【操作】
- 「スタイルをタグにマップ」を実行後、画像のみ選択し「自動タグ」を実行する。
- 【結果】
- テキストフレームごとに内部の見出し、段落要素がグループ化される。テキストの順序は、表示順にならない。テキスト要素と画像要素は分離される。
- テキスト要素、画像とも順序がばらばらになるため、構造パネルですべての要素の順序・階層を修正する必要がある。
- 【調整】
- 要素を適切にグループ化する(章単位、節単位など)。
- テキスト要素の順番を適切な表示順に変更する。
- 画像要素を関連するテキスト要素の前後に移動する。
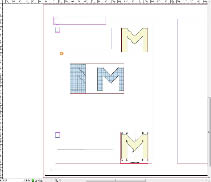
- ※任意のサイズ・位置に配置したテキストフレームにテキストを入力、グラフィックフレームには、外部ファイルの画像を配置する

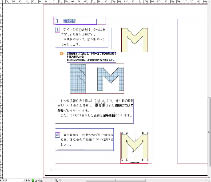
- ※左:テキストフレームのみ表示した例、右:画像のみ表示した例 それぞれのフレームは独立しており関係性を持たない
【図69 配置例】
②1ページ、複数テキストフィールド(テキストは連結、画像は独立)
(a)1ページ、複数テキストフィールド(テキストは非連結、画像は独立)とほぼ同じだがテキストはすべて連結されている。
情報構造化の手順
- 【操作】
- 「スタイルをタグにマップ」を実行後、画像のみ選択し「自動タグ」を実行する。
- 【結果】
- テキストフレームはすべて連結されているので1つのフレームとして扱われ、テキスト要素は1つのグループにまとまる。テキスト要素と画像要素のタグは分離される。
- テキスト要素は1グループ内に順序通り表示されるが、画像は順序がばらばらになるため、構造パネルで画像要素の順序・階層を修正する必要がある。
- 【調整】
- ・画像要素を関連するテキスト要素の前後に移動する。

- 【図70 連結されたテキストフレーム間をライン表示した例】
③1ページ、1テキストフィールド(画像は独立)
1ページ1段組の文庫、1ページ複数段組みの雑誌(文章中心の定型レイアウトページ)で利用される。
情報構造化の手順
(b)1ページ、複数テキストフィールド(テキストは連結、画像は独立)と同じ。
- 【図71 配置例】

- 【図72 テキストフレームのみ表示した例】※位置調整は段落スタイルのインデントなどを利用する
④1ページ、1テキストフィールド(画像はインライン画像かアンカー付きオブジェクト)
画像をインライン画像やアンカー付きオブジェクトに変更し、テキストと関係する位置に配置する。アンカー付きオブジェクトは、テキストフレーム枠内に制限されることなくレイアウトができる。ウェブや電子書籍データに変換する場合に利用される。
情報構造化の手順
- 【操作】
- 「スタイルをタグにマップ」を実行後、画像のみ選択し「自動タグ」を実行する。
- 【結果】
- テキスト要素と画像要素が適切な順序・階層に組み合わされる。
- 【調整】
- この場合、構造パネルで要素の調整作業は不要になる。

- 【図73 テキスト中の画像の位置関係を破線で表示した例】
情報構造化作業を考慮すると、(a)のように複数テキストフレームが連結されていないと非効率である。レイアウトデザインによって(b)複数テキストフレームを連結するか(c)1テキストフレームにするか使い分けると少なくともテキスト要素の情報順序の調整が少なくて済む。(d)はタグ割り当て以前に構造化ができるため理想的ではあるが、通常の画像をインライン画像またはアンカー付きオブジェクトに変換する作業が発生するため、配置画像の点数等から利用するかどうか判断するとよい。