文部科学省委託事業 標準規格の拡大教科書等の作成支援のための調査研究 「拡大教科書の効率的な作成方法について」 平成23年3月
5 教科用特定図書等作成のための汎用性のある教科書データの研究【研究2】
5.1 目的と概要
本章では、【研究1】で各種拡大教科書製作のために一元化した原本教科書DTPデータに含まれる教科書の情報をさらに構造化し、様々な用途に使用可能な教科書データに関する研究を行う。次代の教科書データを作成するための基礎的な研究として本研究を位置づけ、各種拡大教科書やオーダーメイドの拡大教科書の作成、テキスト・図・写真等の抽出、いずれは電子書籍へのデータ変換に至るまでの作業を効率よく行うことを視野に入れている。
従来、原本教科書DTPデータの目的は「出版物」としての教科書を製作することに限られていたが、現在では拡大教科書の作成等でも利用されるようになってきた。これは単にデータを流用するという面だけではなく、「教科書コンテンツ」における媒体の多様化としてとらえることができる。障害のある児童及び生徒のために必要な教科用特定図書等として、標準規格の拡大教科書以外にもオーダーメイドの拡大教科書や点字教科書、マルチメディアDAISY教科書等も注目されている。こうした状況は、各利用者に適したアクセシブルな形態・仕様での「教科書コンテンツ」が求められていることを示す。また、学習・指導方法の変化に伴い、電子黒板やデジタル教科書等の電子媒体への展開も進んでいる。
以上の状況から、本研究では様々な媒体への展開やデータの一元管理が可能な[汎用性のある教科書データ]として位置づけ、その仕様や作成方法を検証していく。
5.2 [汎用性のある教科書データ]の概要と機能
本研究では、[汎用性のある教科書データ]の機能として、以下に対応することを想定している。
- ① 原本教科書のDTPデータとしてそのまま利用できる。
- ② 各種拡大教科書用DTPデータの編集元となる。
- ③ テキスト、図・写真等のデータ等の抽出元となる。
- ④ 電子書籍等、コンピュータ画面や携帯情報端末画面で表示するデータの変換元となる。
【研究1】では、拡大教科書の効率的な作成のため展開しやすいDTPデータを検討した。【研究2】では、さらにそのデータを情報構造化することで、[汎用性のある教科書データ]の作成を行っていく。
![【図40 [汎用性のある教科書データ]の概念】の画像](/wp-content/uploads/ud/h23-03/5-01.gif)
- 【図40 [汎用性のある教科書データ]の概念】
![【図41 [汎用性のある教科書データ]への展開】の画像](/wp-content/uploads/ud/h23-03/5-02.gif)
- 【図41 [汎用性のある教科書データ]への展開】
5.3 検証1:テキスト・図・写真等のデータ抽出
(1)背景と問題点
教科書発行者は教科書の電磁的記録を文部科学大臣等へ提供することが義務化されており、ボランティア団体が拡大教科書を制作する時に用いられている。この際、原本教科書DTPデータから作成したPDFデータが提供される場合がほとんどである。PDFは、基本ソフトを問わず閲覧・印刷することが可能なデータ形式であり、無料閲覧ソフトである Adobe Readerが普及していることから、ウェブ等でも広く利用されている。これは、原本教科書DTPデータそのものを編集するのではなく、その原稿データを使用して別の形態・媒体の教科書を再構築するプロセスとしてとらえることができる。本節では[汎用性のある教科書データ]が原稿データを抽出することが可能かを検証していく。
電磁的記録はボランティア団体が利用しやすく、かつ出版社が提供しやすいものであることが理想的であるが、現在提供されているPDFデータには様々な不具合が生じている。『拡大教科書普及推進会議 第二次報告』においては、「PDF形式のデータについては、そこからテキスト形式のデータをスムーズに抽出することが困難であったり、抽出した文字データが不正確で校正作業が煩雑になったりするという課題がある」と指摘されている。
『平成21年度 教科書デジタルデータ提供の在り方に関する調査研究事業報告書』によれば、ボランティア団体が拡大教科書を制作する場合、個人のコンピュータを利用することが多く、制作環境は統一されていない。PDFデータは Adobe ReaderかAdobe Acrobatを使用して表示が可能だが、多種データ形式でのテキスト書き出しやファイルに含まれるすべての画像データの一括抽出などが行えるのは、高額な専用ソフトであるAdobe Acrobatのみであり、ボランティア団体では必ずしも導入されていない。同様に、教科書発行者による原本教科書DTPデータ作成に使用される Adobe InDesign、Adobe Illustrator、Adobe Photoshop のような専用ソフトも、ほとんど導入されていないのが現状である。
具体的な抽出方法の検証に入る前に、Windows環境 (Windows XPのAdobe Reader X及びWindows 7のAdobe Acrobat 9Pro) において、Adobe InDesign CS5で作成したPDFデータがどのように表示されるかを確認し、現在指摘されている主な問題点を検証した。Adobe Readerを用いてPDFからテキストを抽出するには、(a)テキストコピーと(b)テキスト保存の2種類の方法があるが、それぞれ結果が異なり、いずれも不具合があった。
(a)テキストコピーでは、画面上のテキスト箇所を選択コピーし、ワープロソフトに貼り付けするのだが、文字情報の順序がばらばらになり、レイアウト順にならないという問題が生じた。多数の見出し、段落要素の前後関係を修復するのは大変な作業となり、かえって手間がかかってしまう。(b)テキスト保存の際は、Adobe InDesignページレイアウトデータのテキストフレーム内で、文章の自動折り返し箇所に強制改行が挿入されるという問題が起こった。不要な改行は膨大な数になり、本来の改行と区別して修正を行うのは大変な労力を要する(図42、参照:6.4 PDFデータからテキストを抽出する際の問題一覧)。
一方、画像抽出作業においては、Adobe Readerでは画像の一括抽出機能がないため、多数ある画像ファイルを一つずつコピーし、画像編集ソフト(ペイントなど)に貼り付け保存する必要が生じ、やはり相当の時間と手間を要することになる。また、Adobe Illustrator等で作成されたベクトル画像データは、そもそも抽出ができないという致命的な問題がある(参照:6.5 PDFデータから画像を抽出する際の問題一覧)。
以上の検証から汎用的に利用可能な原稿として①文字情報はテキストデータ、②図・写真等は画像データ、そして③それらの構造を示すレイアウト見本データ、という3種類のデータを提供することを前提に検証を行うことにした。
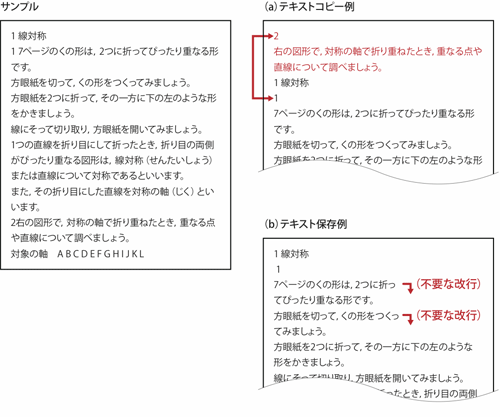
- 【図42 抽出テキストの問題個所】
(2)情報の構造化
「教科書コンテンツ」に含まれるテキストデータを抽出するためには、Adobe InDesignが持つテキストデータ抽出機能を利用する。
テキスト抽出を行うには、まずすべての情報が構造化されている必要がある。この機能を利用して書き出されるデータは複数のタグ付きテキストデータ形式に対応しているが、この中で最も汎用性があり基本ソフトの標準テキストエディタでも編集可能なことから、本研究ではXMLデータ形式を採用した。
XMLデータでは、章・節・項の見出し、本文、注釈、表、箇条書き、目次、索引などの要素となる文字列の前後にタグ記号を付け、文字情報の区別をする。また、一つの意味を持つ要素とタグ名は一対の関係にある。例えば、タイトルとして「小学四年算数」と示す場合は、XMLデータ形式では「<title>小学四年算数</title>」とtitleタグを付け、タイトル要素以外にはtitleタグは使用しない。要素はXMLの規格にもとづいて組み合わされ、順序・階層を示す構造になっている。
原本教科書DTPデータにおいても、要素に対するタグの割り当てを行うことによって、「教科書コンテンツ」を要素ごとにブロック化し、順序が明確化された階層構造をもつデータにすることができる。テキストデータを抽出するにあたっては、このような情報の構造化を行うことが必須条件である。
具体的な作業は、①タグの登録、②タグを要素へ割り当て、③要素の順序・階層を調整、という順番で行っていく。

本検証では、現状の原本教科書DTPデータをAdobe InDesignデータに置き換えたものをサンプルデータとして使用した。このデータは【研究1】で準備と同様の拡大教科書への展開も行いやすい仕様となっている。テキスト要素は、見出し(章・節・頁)と段落(本文、設問等)が中心となるので、これらに対してタグを割り当てる(図44)。テキスト要素は意味内容によって複数タグを使い分け、同じ意味内容を持つテキスト要素に対しては同一タグを割り当てていく。例えば、章見出しの要素に相当するテキストにはすべて同じタグを割り当て、節見出しの要素や本文・設問等の段落要素に対しても同様に行う。また、図・写真等のように、文字情報でないコンテンツに対しても、同様にタグを割り当てる必要がある(図45)。

- 【図43 サンプルページ】
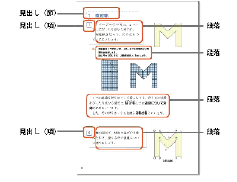
- 【図44 要素例】
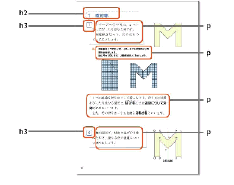
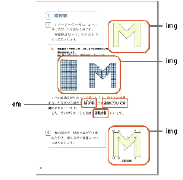
- 【図45 タグの割り当て対象例】
※(株)新興出版社啓林館 『わくわく算数6上』 平成23年度 p.8
①タグの登録
まず、Adobe InDesignのタグパレットを用い、要素ごとに任意のタグ名を登録しておく。本研究では、HTML要素と同様のタグを使用した。
章見出し=h1、節見出し=h2、頁見出し=h3、段落=p、画像=img
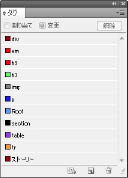
- 【図46 タグパレット】
②タグを要素へ割り当て
タグ名を決定し登録したら、すべてのテキスト要素と画像要素に対して、タグを割り当てていく。テキスト要素や画像を選択し、タグパレットの該当タグを適用する。
この作業は、スタイルをタグにマップ という機能を利用することで一括処理ができる。段落スタイルごとにどのタグを割り当てるかを予め設定しておくことで、自動的に段落スタイル適用箇所のテキストにタグを割り当てることが可能となるので、作業が効率化できる。あらかじめタグの割り付けを踏まえた段落スタイルの設計がされていると、スタイルをタグにマップの作業自体も行いやすい。
③要素の順序・階層を調整
タグの割り当てを行うと、構造パレット にタグが一覧表示される。タグとして表現された要素の順序・階層は、ドラッグで移動させながら調整していく。構造パレット上に示された順序・階層が、書き出し時にはそのままテキストとして反映されることになる。
ただし、Adobe Illustratorなどで作成されたテキストデータを含む図表データをAdobe InDesignのページレイアウトデータ上に配置した場合、図表中のテキストデータを抽出することができない。この図表に含まれているテキストデータを抽出可能にするためには、図表画像に割り当てられたタグに対して属性を追加する。属性名を「Alt」とし、その属性値を図表に含まれている文字情報にする。このように、テキストデータとして認識できない図・写真等のデータに付与する文字情報を「代替テキスト」と呼ぶ。テキストデータを抽出できない図・写真等の画像でも、タグに代替テキストを追加することで、これを含めたテキストデータの抽出が可能となる。
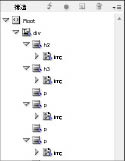
- 【図47 構造パレット】
(3)テキストデータの抽出
(a)XMLデータの書き出し
情報の構造化の作業が完了したデータからは、Adobe InDesignのデータ書き出し機能を利用して各種データを保存することができる。今回は、タグ付きテキストデータであるXMLデータ形式でデータを保存する。保存したXMLデータをテキストエディタで開くと、文字情報がタグとともに表示される。ウェブブラウザInternet Explorerで閲覧した場合も同様である(図48、参照:6.6 DTPデータから抽出したXMLデータ例)。
※ただし、他のウェブブラウザ(Fire Foxなど)で閲覧した場合はタグが表示されないというメリットがあるが、要素ごとに改行がされないために情報が読み取りにくく、本研究には適さないので注意が必要である。

- 【図48 XMLデータをウェブブラウザで表示した例】
(b)XMLデータの利用
このままでは、拡大教科書のテキスト原稿としてコピーすることができない。よって、別途XML表示用HTMLデータを作成し、タグを除いたテキストのみをウェブブラウザで表示できるようにする必要がある。
本来HTMLデータは、文書の実体であるテキストと要素・構造を示すHTML専用タグを組み合わせて記述するが、XML表示用HTMLには文書の実体を記述せず、簡易なプログラム(JavaScript)を記述している。このプログラムによって保存したXMLデータを読み込み、HTML形式に変換し、タグを含めないテキストをウェブブラウザに表示・閲覧できるようにしている。(図49、参照:6.7 XML表示用HTMLをウェブブラウザで表示した例)このプログラムの仕様は公開され広く利用されており、テキストエディタで編集できるので、専用ツールを必要とするプログラムに比較して調整は行いやすい。
本研究では、個別のXMLデータに対して、その都度プログラムを作成していては効率が悪いため、流用が可能なプログラムを作成した。作成したプログラムは、「6.8 XML表示用HTMLコード」に示すコードそのものである。このプログラムを含むHTMLデータをひな形データとし、これを複製して利用する。
- 【図49 XML表示用HTMLを使用しデータをウェブブラウザで表示した例】
(c)作業手順
このテキストデータの抽出とその利用にあたっては、①XMLファイルの保存、②HTMLファイル(ひな形)の複製、③HTMLファイルの記述変更、④HTMLファイルをブラウザで表示、の順で作業を行っていく。

①XMLファイルの保存
情報構造化されたページレイアウトデータからXML書き出しを実行する。XMLファイル名は仮に「kakudai.xml」とする。テキストにルビを含む場合、書き出しオプションでルビをXMLとして書き出し を設定しておく。
②HTMLファイル(ひな形)の複製
保存したXMLファイルと同じフォルダ内に前述のXML表示用HTMLの複製ファイルを設置する。XML表示用HTMLにはプログラムが記述済みであるためプログラムを新たに作成する必要はない。
③HTMLファイルの記述変更(XMLファイル名のみ)
基本ソフトの標準テキストエディタ(メモ帳など)でXML表示用HTMLを開き、プログラムの記述を1か所だけ変更する。該当箇所は「読み込むXMLファイル名」で、保存したXMLファイル名「kakudai.xml」と変更し保存する。一連の作業はすべてテキストの編集作業となり、特別なソフトや操作は不要である。
④HTMLファイルをブラウザで表示
以上のようにして作成したHTMLファイルをウェブブラウザInternet Explorerで表示すると、XMLデータのタグが除かれたテキストのみが、指定した順序通りに不要な改行が入ることなく表示される。ウェブブラウザに表示されたテキストは選択・コピー操作をすることが可能である。
図・写真等の画像に関しては、各外部ファイル名が表示され、代替テキストが設定されているものはテキスト表示もされる。Adobe InDesignの機能を利用してテキストにルビを設定してあるものは、ルビ該当漢字の後に括弧つきでそのふりがなが表示される。(参照:6.7 XML表示用HTMLをウェブブラウザで表示した例)
ただし、XMLデータに書き出される際にテキストの書体情報が失われるので、注意が必要である。ページレイアウトデータで標準フォントと互換性のないフォントや異体字などが使用されている場合、ウェブブラウザやテキストエディタで表示した該当文字は”文字化け”する可能性がある。この場合は、代用可能な文字・記号に置き換えなければならない。(参照:6.2 主な文字化けの事例とその原因、6.8 XML表示用HTMLについて)
“文字化け”の問題は、このテキスト抽出の方法が直接の原因で生じるものではなく、基本ソフトの標準フォントとその他の多くのフォントで扱うことのできる文字セットの非互換性に原因があり、容易に解決はできない。汎用的に利用可能なテキストデータを作成する場合は、このような問題が生じることを認識し、互換性のある文字のみで原稿を作成するか、”文字化け”の生じた箇所を他の文字に置き換えたテキストを原稿として提供するといったことで対処するほかない。
(4)図・写真等の画像データの抽出
図・写真等の画像データは、汎用性のあるJPEGデータ形式での提供方法を検討した。その結果、提供データはページレイアウトデータ(Adobe InDesign)から抽出するのではなく、参照データである外部ファイルを変換して作成することとした。具体的には、Adobe Illustratorのアクション・バッチ処理機能を利用し、複数の画像データを一括処理でJPEG画像に変換する。
作業は、①画像データの準備、②JPEGデータ形式への変換設定、③バッチ処理の実行、の順で行っていく。

①画像データの準備
まず、すべての図・写真等の画像データを1つのフォルダに格納しておく。本検証ではこのフォルダを「A」とし、Adobe Illustratorデータ形式・EPSデータ形式・PNGデータ形式・PDFデータ形式の図形データとAdobe Photoshopデータ形式・EPSデータ形式・JPEGデータ形式・TIFFデータ形式の画像データなど異なるデータを混在させた。
画像フォルダ作成の留意点として、① ファイル名に画像データの拡張子を付与する、② ファイル名の拡張子部分のみが異なるファイルは作成しない、という2点がある。②は特に重要で、例えば「sample.eps」と「sample.tif」という2つのファイルに画像データを格納した場合、変換後はいずれも「sample.jpg」というファイル名になるため、一方が上書きされてしまうのを防ぐ必要がある。
②JPEGデータ形式への変換設定
Adobe Illustratorのアクションとは、複数の操作・設定などを記録し、登録することで一つの命令として扱えるようにする機能で、登録したアクションは繰り返し利用が可能である。
JPEGデータ形式への変換ではAdobe Illustratorの機能「書き出し(JPEGデータ形式)」を利用する。この操作・設定をアクションとして記録し、アクション名「JPEG書き出し」で登録した。「書き出し(JPEGデータ形式)」の設定は、JPEGオプション(画質:10、カラーモード:RGB、解像度:カスタム 200ppi)、書き出し先をフォルダ「B」とした。(参照:6.11 抽出する画像データのカラーモードと解像度)
③バッチ処理の実行
Adobe Illustratorのバッチ処理とは、特定のフォルダ内にあるすべてのファイルに対してある操作を順次実行する一括処理機能のことである。実行内容は、既存のアクションを指定する。
検証用の複数の画像データに対してバッチ処理を行う。画像データの参照先フォルダとアクションを指定し、バッチ処理を行う。参照先フォルダはフォルダ「A」を指定し、保存先(処理後データ)は「なし」を指定(保存でなく、書き出しを行うため)、作成したアクション「JPEG書き出し」を指定し実行する。このようにして、フォルダ「A」内のベクトル画像データを含むすべての画像データが、フォルダ「B」内に指定通りJPEGデータ形式に変換され保存される。
ただし、元画像データを使用するため、原本教科書DTPデータに配置後にAdobe InDesign機能で加工されたサイズ変形、トリミング、効果等の結果は反映されない。
また、ベクトル画像データは、背景が白色のビットマップデータに変換される。白色以外の背景にする場合や切り抜きなどを行う場合は、調整が必要となる。その他、Adobe InDesign上で描画された図形データは変換対象とならない。(参照:6.12 Adobe Photoshopの一括処理機能)
(5)レイアウト見本用データの作成
最後に、原本教科書のレイアウト見本として、Adobe InDesignのPDFの作成機能を利用してPDFデータを作成する。
Adobe InDesignのページレイアウトデータに関する属性を指定するファイル情報でドキュメントタイトルに書籍名、作成者に出版社名を入力しておき、PDFの文書属性を設定しておく。
Adobe InDesign CS5のPDF設定であらかじめよく利用される設定内容を含むプリセットから最少ファイルサイズを選択し、書き出しを実行する。既存の機能として、バージョンはPDF 1.5、カラー画像の画像解像度は100ppi、JPEG圧縮(画質:低)、カラーモードはRGB、フォント埋め込み等の設定がなされている。ファイル名は、文部科学省配布資料の教科書データ提出留意事項に示されている命名ルールに従う。
※[年度]+[出版社略称]+[教科記号]+[学年]+[上・下またはなし]+[最初のページ番号~最後のページ番号].pdf
作成するPDFは、原本教科書のレイアウトを参照することのみが目的なので、オリジナルフォントや特殊記号が使用されている場合も変更の必要はない。また、PDFの画像は低解像度でよいので、スペックの低いPCを利用していたとしても閲覧しやすくなる。(参照:6.10 アクセシブルPDFの作成、テキストデータの抽出検証)
(6)まとめ
テキストデータについては、原本教科書DTPデータの情報構造化 → テキストデータ(XML)の抽出 →XML表示用HTMLのウェブブラウザ表示 → テキストのコピー・保存、という流れで抽出と利用ができる。
利点をまとめると、以下のようになる。
- タグの割り当てをした要素は、すべてテキストデータとして抽出できる。
- 文書の順序どおりにテキストの内容を表示できる。
- 文章中に不要な改行が入らない。
- 図・写真等の画像は、外部ファイル名が表示されるので、文書のどの箇所にその画像が関連づけられているかを把握できる。また、ファイル名を非表示にすることも可能である。
- ウェブブラウザ上で表示された通りの文字情報は、直接コピーが可能である。
- ルビは、対象となる漢字の後に括弧つきで表示できる。
- 図・写真等の画像の中に文字情報がある場合は、代替テキスを指定することで表示が可能である。
- 見出し要素は太字で表示され、要素ごとに改行されるので、文書情報が把握しやすい。
- Adobe InDesignで作成した表組、箇条書き等をHTMLで再現表示することが可能である。
「教科書コンテンツ」にとって、文字情報は最も大切なものである。文字情報を適切なテキストデータ原稿として提供できることは、別の形態・媒体の教科書を作成する際の作業効率の向上につながり、正確な教科書を作成するのに有効である。また、出版社でも原本教科書の最終版テキストデータを保持することができ、電子媒体への制作展開がしやすくなるという利点もある(参照:6.3 出版社が教科書コンテンツのテキストデータを独立したファイルで保持していない理由)。盲学校で使用する点字教科書や教材作成用点訳ソフトの原稿データとしての利用が可能となるなど、さらなる用途も考えられるだろう。そのためには、テキストデータが「教科書コンテンツ」内の全ての文字情報を網羅し、情報の順序を正確に再現していることが不可欠である。
また、画像データを汎用性のあるJPEG形式で提出することで、ボランティア団体等の利便性は非常に高くなる。フォルダにまとめた画像データを一括変換すればよいので、教科書発行者にとってもさほどの負担にはならない。見本用のPDF作成も同様である。
以上の観点から、本章の作業は非常に有効であると指摘できる。
5.4 検証2:電子書籍データへの展開
携帯情報端末で閲覧する電子書籍は、オンライン購入や省スペースの利便性に加えて、容易に文字サイズの変更が可能なため、欧米では高齢者の利用が多い。本研究においても一部の弱視者が利用する有効な媒体として注目している。本節では、原本教科書コンテンツを印刷物以外の媒体へ展開するにあたって、どの程度利用可能かを複数の電子書籍データ形式でサンプルを作成し検証した。
(1)電子書籍への展開検証
電子書籍の表示端末やコンテンツのデータ形式・閲覧ソフト(ビューア)は、多様化・高機能化が進んでいる。表示端末の種類によって使用できないデータ形式もあるが、北米で事実上標準規格となっているEPUBは、ほとんどの表示端末で利用可能である。DTPソフトであるAdobe InDesignでもEPUBデータの書き出しに対応していることからこれを検証対象にした。またいくつかのソフト会社でAdobe InDesignデータを利用して電子媒体向けデータに変換するツールやシステムを提供している。本検証では、株式会社モリサワの電子書籍アプリケーションを作成するツールMCBookを利用し、もう一つの電子書籍データを作成した。いずれも表示端末iPad(基本ソフトバージョン4.2.1)で閲覧検証を行った。
(2)電子書籍データ形式について
(a)EPUB
iPadではEPUBデータを標準の閲覧ソフトiBooksで閲覧する。仕様は公開されており、コンテンツ部分の記述は、ウェブで利用されるXHTML・CSSを利用しているため制作が比較的容易である。閲覧ソフトの機能で文字サイズを変更でき、拡大時には一行に納まらない文字を自動的に次の行に送ること(リフロー)ができる。テキストの縦組み、ルビ表示などには未対応だが、次期バージョン3.0で対応する。またマルチメディアDAYSY教科書の規格であるDAISY4でもEPUB3.0を採用することが決まっている(参照:6.13 EPUBの仕様等)。
(b)MCBook
MCBook は、株式会社モリサワが開発した電子書籍データ形式で、制作システムの呼称でもある。Adobe InDesign や MC-B2 で作成した組版データから、iPhone/iPad及びAndroidスマートフォン用の電子書籍アプリケーションを作成する。主に電子書籍コンテンツ変換ソフト「MCBook Maker」と、iPhone/iPad用電子書籍アプリ生成ソフト「MCBook iPhone Builder」でデータを作成する。作成データには電子書籍コンテンツと閲覧ソフト「MCBookビューア」及びモリサワフォントが含まれる。既存のAdobe InDesignデータを利用することを前提にしており、DTPデータで広く使用されているモリサワフォントの埋め込みができること、縦組み、ルビに対応していることが特徴である(参照:6.14 MCBookの仕様等)。
(3)電子書籍データ作成方法
(a)EPUB
Adobe InDesignの機能を利用し、原本教科書DTPデータからEPUBデータを作成する。
制作工程は、①タグの登録、②要素へタグを割り当て、③要素の順序・階層を調整、④目次の作成、⑤EPUBファイルの保存、⑥EPUBエディターでの調整 の順になる。

①~③DTPデータの情報構造化
①~③は、5.3(2)情報の構造化 で行う作業と同じで、重複して行う必要はない。
④目次の作成
Adobe InDesignには目次作成機能があり、章・節等の見出しを指定し、自動的に目次項目と該当ページの一覧情報を抽出する。この目次は、EPUBデータの目次情報として利用できる。
⑤EPUBファイルの保存
Adobe InDesign からEPUBファイルの保存を行う。保存時に書き出しオプションでメタデータ(出版社名)の指定/配列順(XML構造)の指定/コンテンツ形式(XHTML)や画像変換のデータ形式(JPEG、最高画質)の指定/目次やCSSの作成等の設定を行う。ページレイアウトデータ1ファイルに含まれる全ページのテキスト、画像等は1ファイルのEPUBデータにパッケージされる。
⑥EPUBエディター
EPUBエディターでの調整を行う。EPUBエディターは、Sigil(バージョン0.3.4)を使用した。Sigilは、iPadのiBooksと同等のプレビュー機能をもち、表示確認しながら作業を行うことができる(図50)。SigilでEPUBデータを開き、記述内容やプレビューを見ると、テキスト、図・写真等はAdobe InDesignで構造機能で設定した順序・階層通りに配置されていることを確認できる。また、テキストの段落スタイル、文字スタイルの属性(サイズ、色)もCSSに反映される。画像は、Adobe InDesignのレイアウトサイズで低解像度のJPEGデータが自動作成される(トリミング、効果などを反映)。参照データが同じでも複数ページに配置されている画像は、配置数分作成される。
籍名・出版社名等のメタ情報の登録、目次の編集を行う。レイアウトの調整は必須となる。章ごとの改ページ指定は、Sigilの機能を利用すれば容易に指定できるが、コンテンツ、レイアウト編集はHTML、CSSコードの編集作業が必要となる。ビューアで利用可能な標準フォントに含まれない文字は、文字化けが生じるため文字の置き換え等の対処が必要である。Adobe InDesignの画像タグにAt属性を追加してもEPUBには反映されないため、iPadのアクセシビリティ機能を利用して音声読み上げに対応することを考慮するとEPUBの編集時に画像の属性に代替テキストを追加する必要がある。
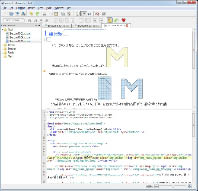
- 【図50 Sigilの編集画面】
※画面上:プレビュー、画面下:HTMLコード
(b)MCBook
MCBookを使用し、原本教科書DTPデータからiPad用アプリケーションデータを作成する。
制作工程は、Adobe InDesignのページレイアウトデータを①MCBookタグ付きテキストデータに変換、②編集、中間ファイルを作成、③iPad用アプリの作成 の順になる。

※MCBookでは、Adobe InDesignの段落スタイルをそのままタグに変換し、MCBook中間データを作成する。Adobe InDesignのタグ・構造等の機能は利用しない。
①Adobe InDesignデータの変換
はじめにMCBook Maker(Windows)を使用し、プロジェクトデータを作成する。プロジェクトデータには、テキスト、画像、フォント等電子書籍に必要なデータを格納する。次に対象とするAdobe InDesignのページレイアウトデータを指定し、タグ付きテキストに変換したコンテンツをプロジェクトデータに追加する。変換時には、Adobe InDesignの段落スタイルをMCBookのスタイルシートとして取り込むことができる。タグ付テキストデータは、MCBook独自のもので、このソフトでのみ編集が可能である。画像も、JPEGデータ形式に変換された形で自動作成される。Adobe InDesignのレイアウトサイズでトリミング・効果などを反映した画像になる。
②編集、中間ファイル作成
タグ付きテキストの記述内容を編集し、要素の順序の調整、改ページ、目次リンクの設定等を行う。埋め込みフォントの選択、スタイルの編集、画像の追加などレイアウトや表現に関する設定も行う。iPadを含めた各種端末サイズのプレビュー機能をもち、表示確認しながら作業を行うことができる。編集後、中間ファイル(MMCデータ形式)を作成する。このファイルには、テキスト、画像、フォント等のデータがパッケージされる。
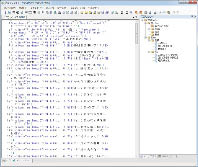
- 【図51 MCBook Maker 編集画面】※Adobe InDesignデータのコンテンツは、MCBookタグ付きテキストに変換される。


- 【図52 プレビュー】
③iPad用アプリの作成
MCBook Builder(Mac)を使用し、中間ファイルと書籍情報、アイコン画像等を設定し、iPad用アプリケーションを作成(ビルド)する。
5.5 検証1・検証2の結果
検証1:テキスト・図・写真等のデータ抽出及び検証2:電子書籍データへの展開では、教科ごとにサンプルデータを作成した。国語(教育出版株式会社 ひろがる言葉 小学国語 3上 平成23年度)、算数(株式会社新興出版社啓林館 わくわく算数6上 平成23年度)、理科(株式会社新興出版社啓林館 わくわく理科3 平成23年度)の一部のページをサンプルとした。いずれも現状の原本教科書DTPデータをAdobe InDesignデータに置き換えたものを用意し、これに対して検証を行った。以下に、教科ごとの検証結果を示す。
(1)国語
国語の特徴は、章単位で1つの物語、小説などの読み物がまとまっており、比較的シンプルな構成になっているため情報構造化しやすい(参照:3.3 教科別のレイアウト検証)。文字情報が中心で、図・写真等は少なく、物語の挿絵にイラストが使用されている程度であり、テキストは、縦組みで新出漢字等にルビがふられている。


- 【図53 原本教科書イメージ】
※教育出版(株)『 ひろがる言葉 小学国語 3上』 平成23年度
①テキストデータの抽出
文書構造がシンプルなので情報構造化しやすい。新出漢字や、注釈等は、原本教科書では同一ページ内に示されるが、テキストデータでは章ごとの末尾にまとめて示した。本文中の新出漢字と欄外に示されるその読み・意味などの補足情報の関連付けはできていない。
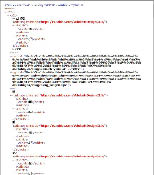

- 【図54 ウェブブラウザでの表示例】※左:XMLの表示例、右:HTMLを利用しテキストのみ表示した例(Internet Explorer8で表示)
②電子書籍 EPUB
現状は横組みで表示している。組方向が変わることで文字や表現の変更を必要とする場合がある。例として縦組みでのみ使用するダブルミニュート(〝〟)などの記号や見出しの装飾的な表現などがある。Adobe InDesignから作成するEPUBデータにはルビの情報が含まれない。サンプルでは電磁的記録(テキストデータ)を利用し、ルビを対象となる漢字の後に括弧付で追記した。


- 【図55 iPadの閲覧ソフトiBooksで表示した例】
③電子書籍 MCBook
縦組み・ルビ・縦中横等に対応しており原本教科書に近い表現が可能である。テキストと画像を同じ画面で表示することができないが、挿絵画像の場合が多いため特に支障はない。現状では埋め込み可能な書体の中に教科書体がないため本文には明朝体(リュウミン L-KL)を使用している。文字サイズを拡大すると、書体の違いにより読みやすさが異なることが明確になる。





- 【図56 iPadで表示した例】
(2)算数
算数の特徴は、章の中を複数の節で分けられている(サンプルでは、「1線対称」が節見出しにあたる)。このページで項は、番号のみで示されており、設問になっている。章・節・項・番号付きリストというように階層が深くまで細分類化されている。(参照:3.3 教科別のレイアウト検証)。計算式や図が多く、文章による説明は少ないが、計算式の記号、単位記号が多数出現する。図を利用した説明・設問が多く、図中には位置や部分を説明するため記号が記されており、その説明や設問中にもその記号が使用されている。


- 【図57 原本教科書イメージ】
※(株)新興出版社啓林館 『わくわく算数6上』平成23年度
①テキストデータの抽出
四則演算・単位などの記号は標準フォントに含まれるものが多いが、計算式の表現の中にはテキストだけで再現することが困難なものがある(分数の括線、組み立て割り算の記号等)。また図中の記号の中には、標準フォントと互換性のないオリジナルフォントや商用フォントの特殊記号が使用されている場合があり、これらは文字化けするため文字の置き換えなど調整が必要になる。


- 【図58 ウェブブラウザでの表示例】
※左:XMLの表示例、右:HTMLを利用しテキストのみ表示した例(Internet Explorer8で表示)
②電子書籍 EPUB
電磁的記録(テキストデータの抽出)と同様に数式、記号の問題がある。EPUBはXHTMLでコンテンツを記述しているため数式の記述言語MathMLにより数式を表現できるが、詳細の検証は行っていない。Adobe InDesignでのタグ割り当てが複雑化することが予想され、別途表現方法の研究が必要である。

- 【図59 iPadの閲覧ソフトiBooksで表示した例】
③電子書籍 MCBook
MCBookではテキストと画像を同じ画面で表示することができない。設問と関係する図が同一画面内で表示できないため1画面で内容を把握しにくい。埋め込みが可能なモリサワフォントはAdobe-Japan1-6の文字セットに対応しているため、多くの記号・異体字を表示することができる。Adobe-Japanの文字セットに対応したOpenTypeフォントであれば、Adobe InDesignの機能を利用し、多くの異体字・記号を入力することができる。例えば、サンプル中に「○付のく」の記号が使用されており、Adobe InDesignでは入力・表示が可能である。ただし、Adobe InDesignからMCBookタグ付きテキストに変換された時点で文字化けが生じ、記号はひらがなの「く」になるため、該当する記号のコードを指定し、修正する必要がある。分数の括線、組み立て割り算等は、再現できないため、画像にせざるを得ない。






- 【図60 iPadで表示した例】
(3)理科
図・写真等が多用され、同時に文字情報も多い。文字組版は定型的ではなく、レイアウトは複雑で多様である。章・節の関係は比較的明確だが、見開き2ページ単位で情報が詰め込まれており、項にあたる要素が多い。要素の多さから情報構造化は複雑になりがちである。また見開き2ページ全面に写真が配置され、その上にテキスト・画像がレイアウトされている場合も多く、要素の順序を特定することが難しい場合がある。
(参照:3.3 教科別のレイアウト検証)


- 【図61 原本教科書イメージ】
※(株)新興出版社啓林館 『わくわく理科3』平成23年度
①テキストデータの抽出
節の単位で見開きまたは1ページで情報がまとまっている場合が多い。この中で文書情報は、直線的に連続しているとは限らない。本文の続きにイラストに含まれる文字情報(吹き出し)が続くこともある。情報構造化の前に十分なコンテンツの理解が必要である。図中に含まれる文章をテキスト抽出可能にするためには、タグ属性に代替テキストを追加することが必要になる。サンプルでもイラストの吹き出し中に含まれる文章は、その画像要素のAlt属性に代替テキストとして追加している。理科の場合、このようなコンテンツに必要な文字情報が、図表に含まれていることが多いので、そのぶんAlt属性の追加も多くなりがちである。
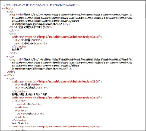
- 【図62 ウェブブラウザでの表示例】※左:XMLの表示例、右:HTMLを利用しテキストのみ表示した例(Internet Explorer8で表示)
②電子書籍 EPUB
レイアウトが複雑なためEPUBで表現可能なレイアウトに変更することが必要になる。EPUBに含まれるXHTML、CSSをかなり調整することになる。図・写真等に文章として文字情報が含まれる場合が多い。この図に含まれる文字情報が読み取れない場合、画像サイズを大きくするか文字サイズ・書体を変更して画像データを作成しなおす必要がある。
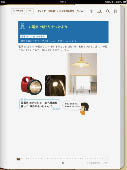


- 【図63 iPadの閲覧ソフトiBooksで表示した例】
③電子書籍 MCBook
MCBookの仕様上、テキストと画像を同じ画面で表示することができない。図・写真等が多用されているため改ページが多くなる。また文章と関係する図が同一画面内で表示できないと内容を把握しにくい。






- 【図64 iPadで表示した例】
5.6 [汎用性のある教科書データ]まとめ
5.4 検証1・検証2の結果から特に各電子書籍データ形式で対応する表現・機能に制限があるため教科によって適さないものもあるが、各データ形式への展開自体は可能であることがわかった。検証1、検証2とも原本教科書DTPデータ(ページレイアウトデータ)の『情報構造化』の作業を必要とし、このデータから抽出するテキストデータや書き出す電子書籍データ(EPUB等)は共通して『タグ付きテキストデータ』の形式になる。教科用特定図書等作成のための[汎用性のある教科書データ]は、(a)原本教科書DTPデータを元とし、(b)各種拡大教科書など印刷用途のDTPデータへ展開がしやすく、(c)汎用性のある『タグ付きテキストデータ』を作成しやすい(d)『情報構造化』されたデータであると考えられる。
(1)[汎用性のある教科書データ]の展開性
次の図65に汎用性のある教科書データと展開データの関係やそのデータの用途等を示す。[汎用性のある教科書データ]から展開するデータの種類は、大まかにDTPデータ(図左下)、タグ付きテキストデータ群(図右上)になる。
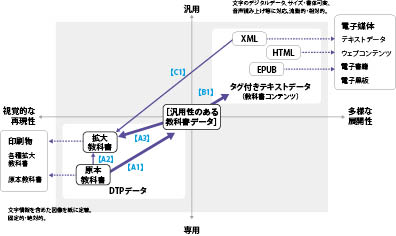
- 【図65 汎用性のある教科書データと展開データの関係】
印刷専用のDTPデータは、ページレイアウトソフトでの表示イメージをそのまま印刷で再現し、文字や図・写真等を図像として用紙に固定する。
タグ付きテキストデータ群には、複数のデータ形式がある。DTPデータから形式の異なるタグ付きテキストデータへ書き出した(図中【B1】)後、別のソフトで編集し、各種電子媒体のコンテンツデータとして使用する。データは端末の閲覧ソフトにより閲覧し、ユーザによる文字サイズ・色などの変更が可能である。マルチメディアDAISY教科書の次期規格DAISY4は、EPUB3.0を採用することが決まっており、今後EPUBデータの展開に期待できる。
電子媒体への展開以外にも、XMLデータなどを教科書コンテンツのテキスト原稿とし、DTPデータに利用する(図中【C1】)こともできる。体裁・レイアウトの異なるオーダーメイド版の拡大教科書DTPデータ作成、点字教科書の作成などに応用できる。
※原本教科書DTPに拡大教科書を効率的に作成するための基本条件が備わっていれば図65の【A2】の流れで制作を行うことができる。そうでない場合は、一旦[汎用性のある教科書データ]化して(図65の【A1】)、拡大教科書を作成する(図65の【A3】)。
![【図66 [汎用性のある教科書データ]を利用した展開例】の画像](/wp-content/uploads/ud/h23-03/5-57.jpg)
- 【図66 [汎用性のある教科書データ]を利用した展開例】
(2)[汎用性のある教科書データ]の基本的なデータ仕様
検証から考えられる[汎用性のある教科書データ]の基本的な仕様を①DTPデータ構成、②使用フォント、③文字組版、④情報構造に分類して示す。
①DTPデータ構成
ページレイアウトデータは、1冊のすべてのページデータを含めた1ファイル構成とする。
各ページ共通の体裁、情報は、マスターページを利用する。
図・写真等の画像データは、Adobe Photoshop、Adobe Illustratorで別のファイルとして作成し、ページレイアウトデータに配置(リンク)する。画像データは、1つのフォルダに格納する。
②使用フォント
標準フォントとの互換性の高いフォントを利用したデータであること。
③文字組版
ページレイアウトデータ中のすべてのテキストに段落スタイル・文字スタイルを適用する。
④情報構造
レイアウト要素にタグを割り当て、これを適切な順序・階層に組み合わせた状態にする。
①~③は、拡大教科書DTPデータを効率的に作成するための条件でもある。①1ファイル構成とすることは複数ページを一括処理するための前提である。②使用フォントは、特にタグ付きテキストデータに変換した(標準フォントに置換される)時にも文字化けを生じないよう考慮が必要である。③文字組版にスタイルを利用することは、DTPデータ制作時に有効であり、拡大教科書作成時にサイズ・書体変更の一括処理を可能にする。また、情報構造化の作業工程で、スタイルに応じた一括タグ割り当て機能にも利用できる。スタイル作成時には後工程の作業を踏まえた設計が必要である。④情報の構造化は、DTPデータ以外のタグ付きテキストデータ形式などに変換する場合、必須である。最適な情報構造にしておくことで変換後のデータを全情報を網羅した正確なものにすることができる。
(3)情報構造化の作業について
従来の出版用DTPデータ制作工程に情報構造化の作業は含まれない。しかしDTPデータ作成時のページレイアウトデータのテキストフレーム・画像の配置方法によって情報構造化作業及びタグ付きテキストデータ調整の難易度に影響する(参照:6.15 テキストフレーム・画像の配置方法による情報構造化作業の違い)。今回の検証で電子書籍データ形式の対象としたMCBookは、Adobe InDesignのタグ・構造をタグ付きテキストデータ変換時に利用しないが、テキストフレーム・画像の配置や連結方法は変換後の情報構造に大きく影響する。
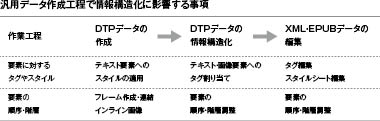
- 【図67 タグ付きテキストデータの構造最適化に影響する事項】
このようなデータの作成方法以外にコンテンツや視覚表現によって情報の順序・階層が判別できず情報構造化の作業が困難な場合がある。明確な文書構造をもつコンテンツとデザイン・レイアウトの場合、DTPデータの情報構造化も行いやすい。教科ごと編集意図の異なる教科書でコンテンツや視覚表現の定型化は困難だが、[汎用性のある教科書データ]の情報構造化の作業には影響する。
情報構造化が適切に行われていれば、その後工程となるタグ付きテキストデータの編集で情報の順序・階層の調整を必要としない。現状では情報構造化を踏まえたデータ作成、コンテンツや視覚表現がなされていないため、今後はこの作業効率化を踏まえたDTPデータの作成について別途検討が必要である。
(4)教科用特定図書等作成のための汎用性のある教科書データの研究【研究2】まとめと考察
教科書コンテンツを多目的に利用する場合、元となる原本教科書DTPデータを同じDTPデータ形式で再編集する場合を除いて、汎用性のあるデータ形式へ変換する必要がある。変換後のデータには、すべての情報を網羅し、正確な情報の順序・階層を持ち、文字・記号類の再現が確保されることが重要となる。これは原本教科書DTPデータを情報構造化することで概ね対応できる。多様な展開が可能になるのと同時にデータを一元化管理できる利点は大きい。特にDTPデータ(専用データ)から抽出されたテキストデータ(汎用データ)の利用範囲は広く、多様な媒体への展開が考えられる。
さて、検証には電子書籍を取り上げたが、文字サイズの変更ができ、紙にくらべてかさばらない等媒体特性に注目はしているものの具体的な利用目的・環境・方法は想定していない。検証結果のとおりその仕様・機能から原本教科書の再現には適さないものもあり、今後電子媒体への展開では、その利用目的の設定とそれに応じた編集方針、リデザイン等を考慮する必要がある。
一方で、拡大教科書作成時のレイアウト変更作業や電子媒体の仕様・機能を考慮し、原本教科書の情報構造やその視覚表現・レイアウトデザインをシンプルで展開しやすくするということも考えられる。しかしながら、これらは教科別・学年別教科書の目的、編集意図に応じて制作されているため、現時点では容易に対応できないと思われる。
今後、教科書コンテンツの電子媒体への展開が進むことが予測される。現状の小・中学校の見る教科書の表現を汎用性のある電子書籍データに再現することは困難であるが、章節項などの情報構造が明確な文字情報中心のコンテンツで直線的な情報の流れをもつシンプルなレイアウトであれば再現性を確保しやすい。教科では国語・社会、学年別では小学校より中学校向け教科書が適している。また今回は対象としていない高等学校の教科書・教材は、さらに適性が高いと考えられる。高等学校の弱視生徒の拡大教科書等の教科用特定図書等の潜在的な要望は高く、小・中学校以外でも[汎用性のある教科書データ]の仕様は、活用できると考えられる。